AET
vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations
rather than Data
 Guo-Jun Qi
Guo-Jun Qi
Laboratory for MAchine Perception and LEarning (MAPLE)
Abstract: The success of deep neural networks often relies on a large amount of labeled examples, which can be difficult to obtain in many real scenarios. To address this challenge, unsupervised methods are strongly preferred for training neural networks without using any labeled data. In this paper, we present a novel paradigm of unsupervised representation learning by Auto-Encoding Transformation (AET) in contrast to the conventional Auto-Encoding Data (AED) approach. Given a randomly sampled transformation, AET seeks to predict it merely from the encoded features as accurately as possible at the output end. The idea is the following: as long as the unsupervised features successfully encode the essential information about the visual structures of original and transformed images, the transformation can be well predicted. We will show that this AET paradigm allows us to instantiate a large variety of transformations, from parameterized, to non-parameterized and GAN-induced ones. Our experiments show that AET greatly improves over existing unsupervised approaches, setting new state-of-the-art performances being greatly closer to the upper bounds by their fully supervised counterparts on CIFAR-10, ImageNet and Places datasets.
Formulation
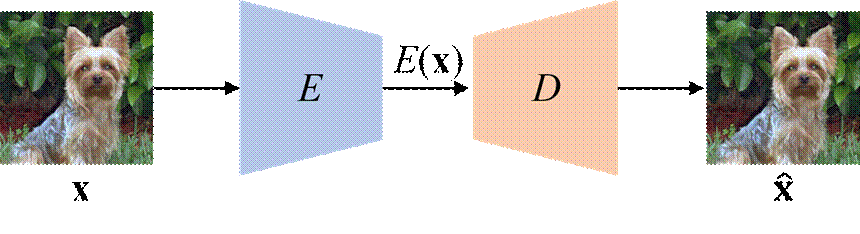
(a) Auto-Encoding Data (AED)
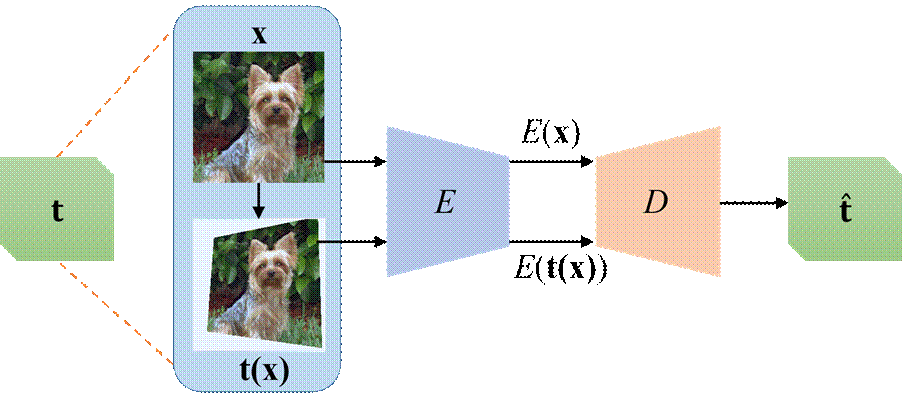
(b) Auto-Encoding Transformation (AET)
Figure 1: An illustration of the comparison betweeen AED and AET models. AET attempts to estimate the input transformation rather than the data at the output end. This forces the encoder network E to extract the features that contain the sufficient information about visual structures to decode the input transformation.
Figure 1 illustrates our idea of auto-encoding transformation (AET) in comparison with the conventional auto-encoding data (AED). We build a transformation decoder D to reconstruct the input transformation t from the representations of an original image E(x) and the transformed image E(t(x)), where E is the representation encoder.The least-square difference between the estimated transformation and the original transformation is minimized to train D and E jointly. For details, please refer to our paper [1].
Results
We performed experiments on CIFAR-10, ImageNet and Places datasets. Figure 2 below illustrates the used architecture on CIFAR-10. For more details about implementation, please refer to [1].
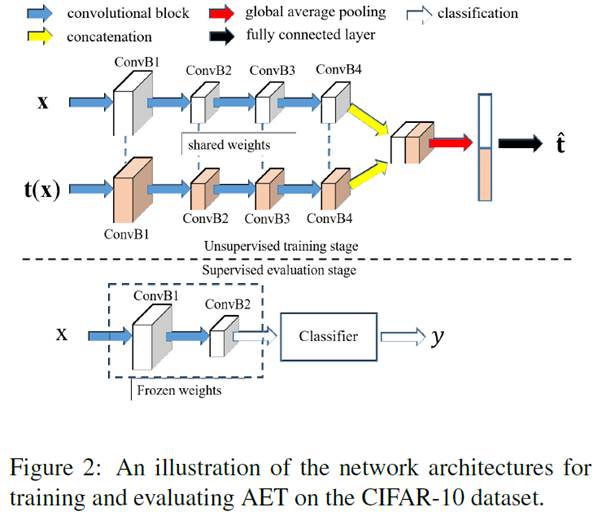
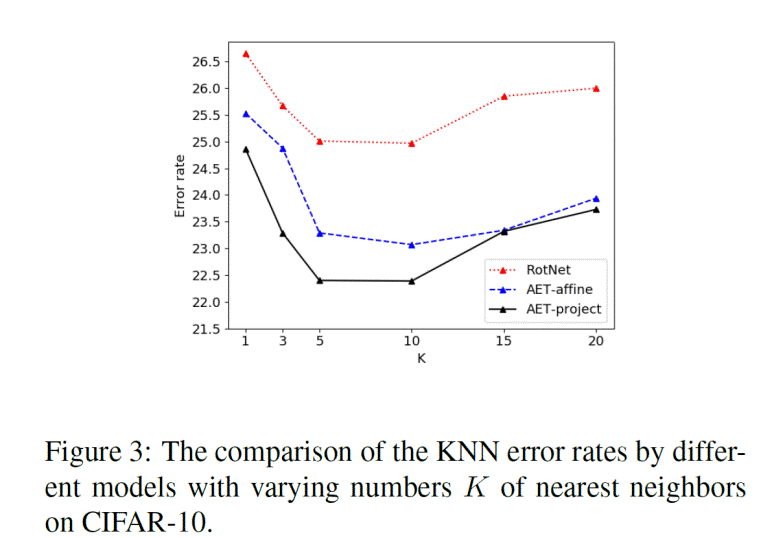
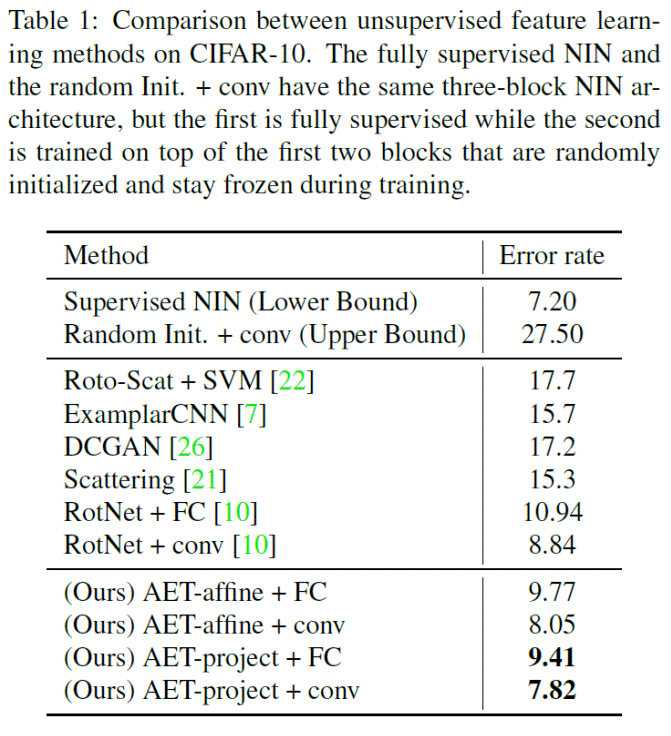
Table 1 below reports the experiment results on CIFAR-10 with a three-layer nonlinear classifier being trained on top of the first two blocks that are pretrained by AET.
We also used model-free KNN classifier to evaluate the unsupervised representations, and the results still show the consistently outstanding performance by AET over the compared state-of-the-art method as shown in Figure 3 above. To our best knowledge, we are the first to conduct such a model-free evaluation on unsupervised methods without training a classifier.
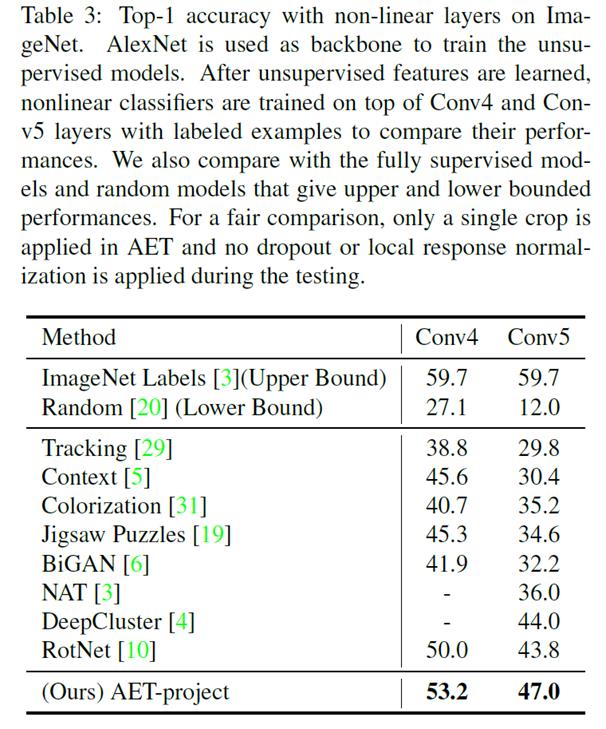
We also train Alexnet by AET and evaluate the performance of learned representations based on Conv4 and Conv 5 output feature maps. The proposed AET can significantly close the performance gap with the fully supervised network as shown in Table 3 in the paper below.
More experiment results on ImageNet and Places datasets can be found in our paper [1]. Readers are also invited to test our code released at the following github page.
Citation
[1] Liheng Zhang, Guo-Jun Qi, Liqiang Wang, Jiebo Luo. AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data, in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, June 16th - June 20th, 2019. [ pdf ]
Code
https://github.com/maple-research-lab/AET
March 25, 2019
© MAPLE Research