- [Embodied AI]
This project originated from a research plan supported by Natural
Natural Science Foundation (NSFC). We developed embodied AI
models able to predict the future dynamics of robots and their
interactions with the world. It combines the ability of video
predictions, action planning and their alignments with the prediction
of physcial processes to complete instructed tasks. We conceived
the Embodied Alignment Problem
aiming to align the embodied AI models with the powerful LLMs so new
models can predict the physiclal world futures not only in low-level
actions but also in language-and-symbol tokens explannining from the
physical and abstract perspectives.
 (a) RoboEgo human demonstration collection with aligned views of robots 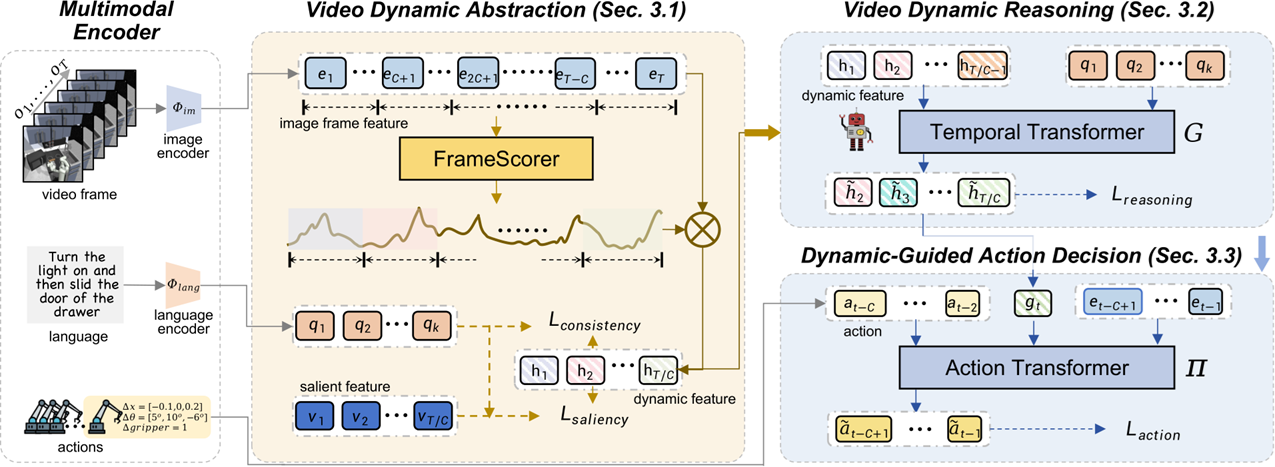 (b) Aligning saliency of video dynamics with task instructions - [Auto-Evolution of AI Agents] We developed auto-evolving of AI agents,
including their system prompts, contexts and memory systems so that
they can accumulate knowledge and experiences from past interactions
with the world[ pdf].
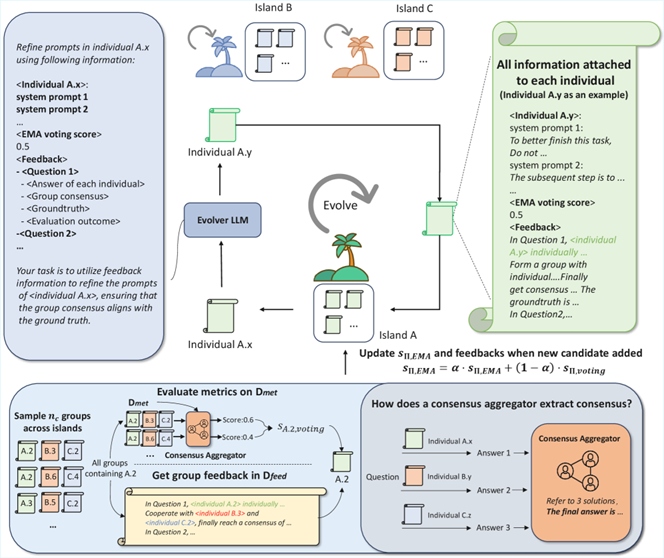 (a) Evolutionary process in the voting stage of Consensus Evolve (C-Evolve)  (b) C-Evolve progressively incorporates the necessary considerations for instruction following through evolution.
- [Efficient AIGC Models and Reinforcement Training Algorithms]
We study how to make AIGC models more efficient in generating
multimodal contents over visual and language data. More details about
the project will be updated.
- 1) Score Implicit Matching (SIM) and Flow Generator Match (FGM):
One-Step Diffusion and Flow-based Generative Models that are able
to generate images with only a single step. That is super
efficient than many SOTA text-to-image diffusion and flow-matching
models. Being able to generate visual contents in one step plays a key
role in many real-time and/or resource limited applications.
Both are data-free since there is no need for training data to
learn these one-step generators. See more details in our papers [pdf] [pdf] and projects [github].
The above figure
demonstrates some generated images by our one-step SIM-DiT-600M model,
compared with those from the 14-step PixelArt-alpha diffusion model.
Our model outperforms multi-step generative model with a single
step.
- 2) Diffusion Model Reinforcement Training - Time Prediction Diffusion and Flow-based Models (TPDM)
for Faster and Better AIGCs. We present a brave new idea of
training a module to explicitly schedule which diffusion
time shall be taken in the next sampling step. We made it possible by
parameterizing diffusion/flow time with Beta distribution in an action
space where reinforcement learning is applied to learn the optimal
diffusion/flow time to take from a reward model. Based on how
complex and
how much visual details shall be generated, the TPDM can
adapt itself with the per-sample diffusion time schedules used to
generate images.
- Interestingly, it implements a Reinforcement FineTuning (ReFT)
strategy -- Diffusion Time Steps can be viewed as "Chain Of Thoughts
(COTs)" in diffusion models that reason about how to generate images
step by step over a reverse diffusion course. Such a ReFT
algorithm makes it possible for diffusion models to generate high
quality images from long and complex prompts by dynamically exploring
possible reverse diffusion processes and thus adaptinig the generative
procedure on the fly. Check our report [pdf] and [github] project page.
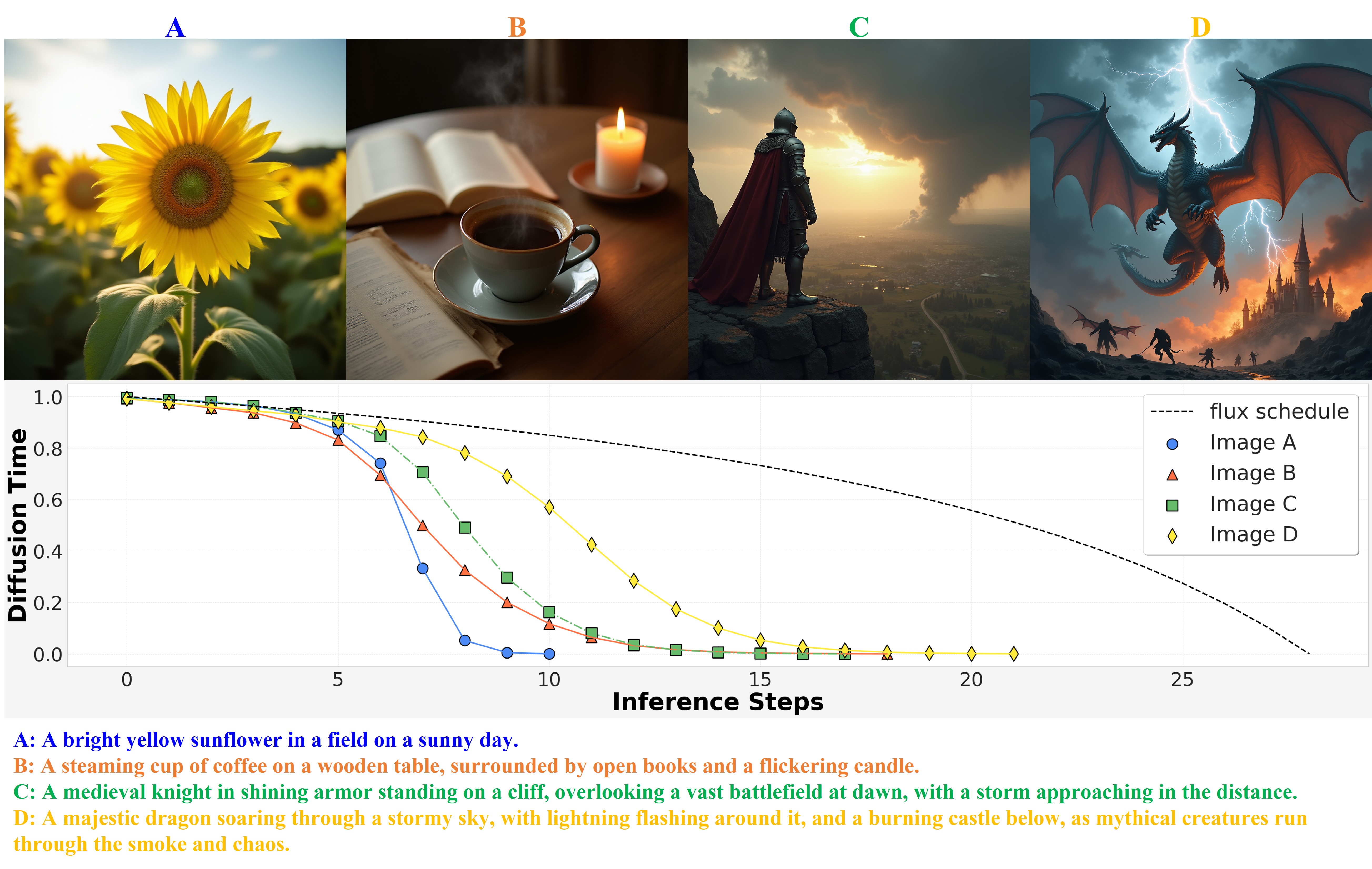
(a) Four examples of how TPDM dynamically schedules diffusion time
based on different levels of complexity in generating multimodal
contents. TPDM samples images more rapidly than the benchmark
flux schedule. The longer and more complex text prompts, the
more slowly the diffusion/flow time decreases from 1 to 0 yet still
much faster than flux; this allows the model to adjust its
schedule to generate visual details adaptively to the prompt
complexity.
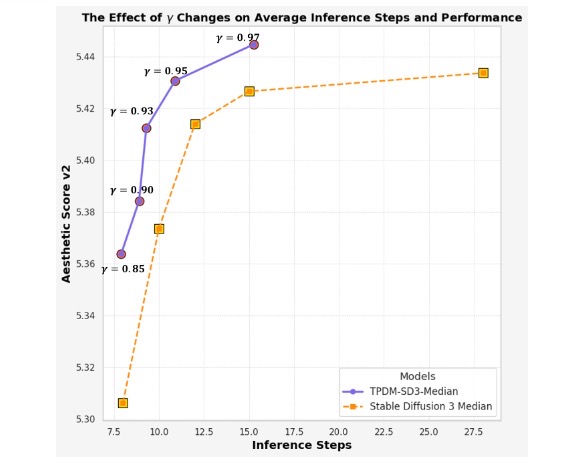 (b)
Plot of aesthetic scores vs. the number of inference steps required to
generate quality images. As shown, TPDM is able to generate
better images of higher aesthetic scores with fewer inference steps
compared with SD3 benchmark.
- [AIGC for Multimodal Content Generation]
We are devoted to developing character-centric and story-telling video AIGC
for generating both 2D and 3D multimodal contents. The generated
assets are highly controllable in 2D and 3D spaces, being
rendered with high-fidelity physically-correct details. They provide gate way
to simulating how characters of mentioned entities in prompts should
interact with the real world.
- 1) AvatarGPT/UltrAvatar:
taking text-prompts as inputs, it gereates animatable avtar faces with
high quality textures, normal maps, roughness and other PBR textures.
This makes it possible to generate diverse high-quality real and/or
unreal avatars in a more affordable fashion, who can be animated
to perform high fidelity expressions. See more visualized results at
our project homepage [github].
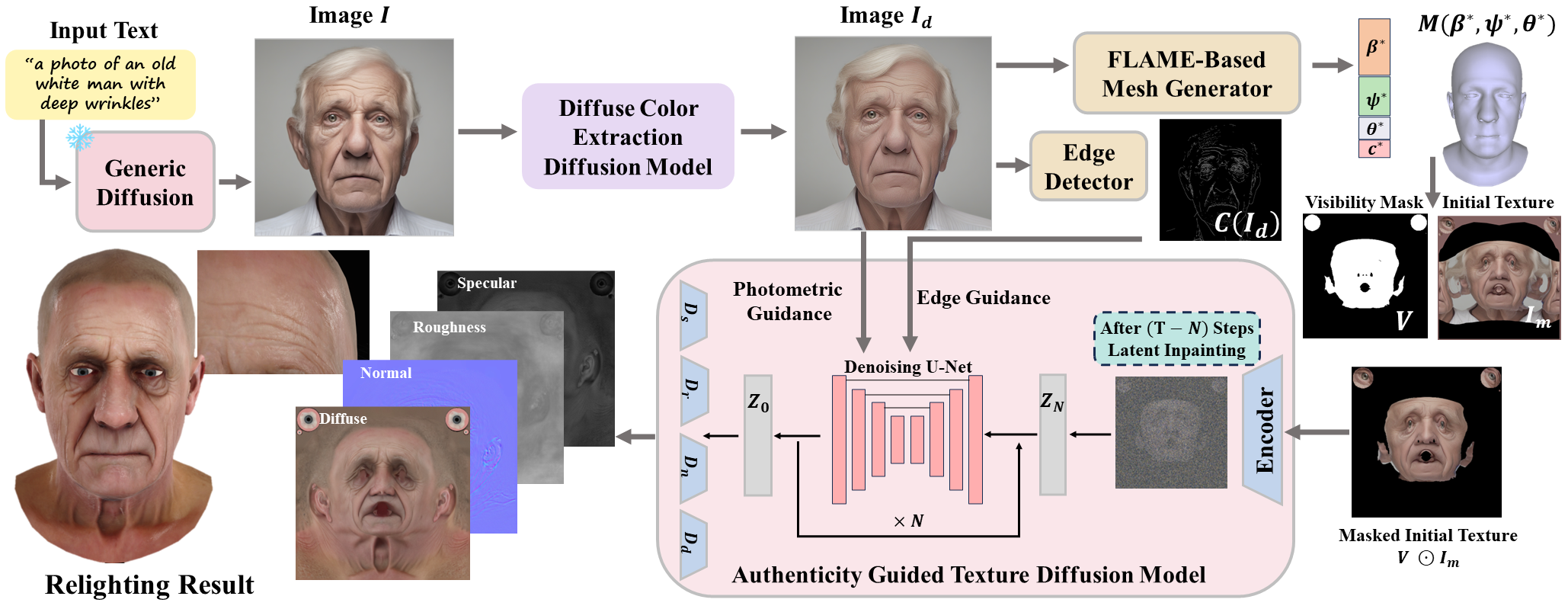
(a)
Pipline for UltrAvatar generating photo-realistic avatar with
high-resolution PBR textures including diffuse colors, normal maps, and
roughness. Visualized results are shown at [ github].
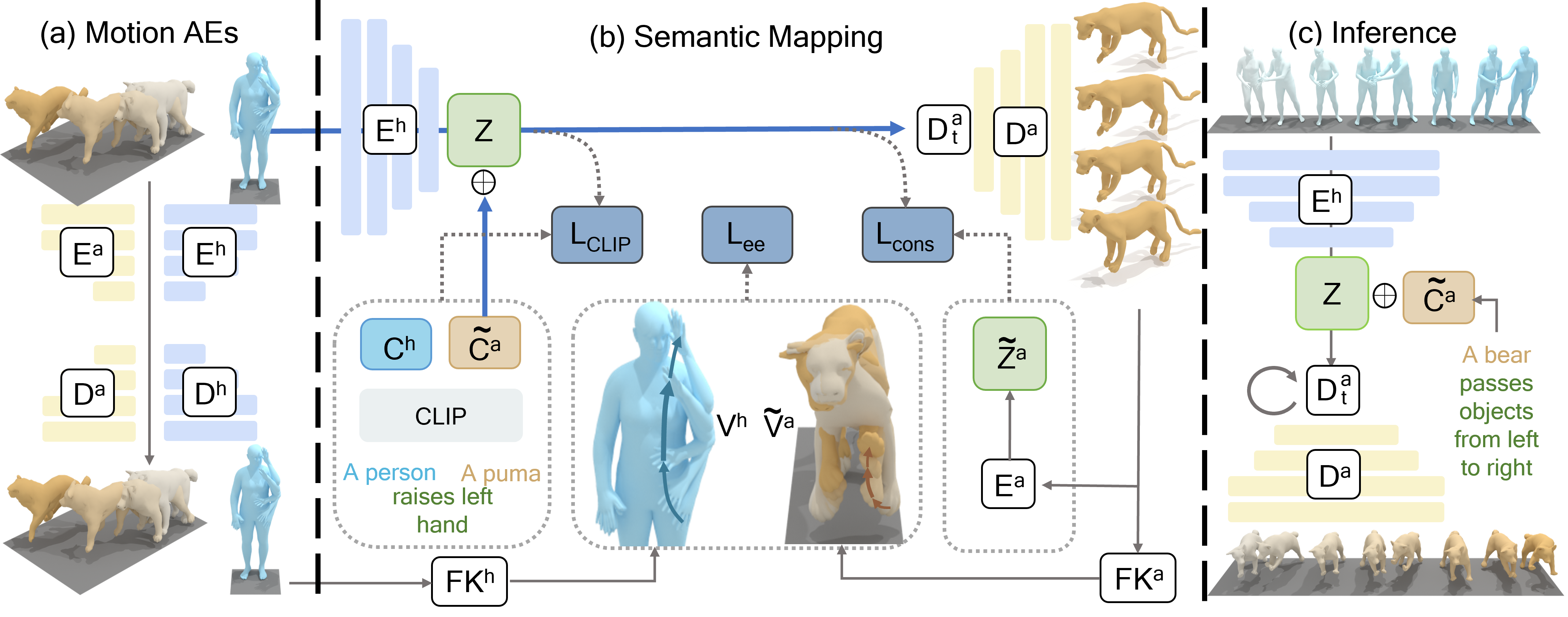
- 2) MotionGPT/OmniMotionGPT:
It generates animal 3D meshes from text prompts, which can be animated
by human-like motions. It does not rely on a large-scale animal
text-motion training dataset, but instead utilizes human text-motion
datasets to make the animals act like humans. See more visualized
results at our project homepage [github].
(b) Pipline for OmniMotionGPT generating animal meshes and human-like
motions. Visualized results are shown at [ github].
- 3) AnimateGPT/PoseAnimate:
it proposes a zero-shot Image-to-Video generation framework to animate
character-centric videos from a single image with pose guidance.
It is zero-shot because it does not need additional video dataset
to create high-fidelity videos aligned with given pose sequences [pdf].
 (c)
PoseAnimate generating character-centric videos from a single image
(source), with their poses aligned with given guidances [ pdf].
- [Light Stage for Avatar Modeling and Animatioon] We have three-fold goals for this project: 1)
developing next-generation of light stage to capture high-defnite
meshes, 4K texture and normal maps; 2) building new generation of AIGC
technologies to enable automatic modeling, rigging and animation of
digital avatars in virtual environments; supporting multimodal AIGC
from text to expressions and human motions; 3) highly efficiently
rendering and relighting details of avatar skins, materials of
environments and their interactions. Welcome to contact us to try live demos.
- 1) Next-generation of light stage
and high-definite modeling of 4K details
- A light stage is
built to enable capturing of multi-view/multi-expression of human face
and body. It is based on stereo and photo-metric techniques, allowing
to capture high-definite meshes with millions of vertices, and 4K
texture and normal maps. The light stage enables us to capture
various expressions of a performer from multiple views. The captured
data allows to model and animate an avatar based on AI technogies. 4K
texture and normal maps are captured.

(a) light
stage for capturing high-definite data
(b) multi-view
capturing of various expressions (c) 4K texture and normal maps.
- 2) AIGC-based modeling, rigging
animation of avatars in virtual environments. Our AI-based
algorithm learns a light-weighted model to animate fine-details of
expressions and motions for an avatar from a smart phone. Multimodal
AIGC model is also built to animate avatars from texts subject to
physcial constraints.
 
(d) AI-enabled modeling, rigging and
animation of digital avatars
- [Self-Supervised/Unsupervised
Network Pretraining] Using self-supervised
methods for
unsupervised, semi-supervised and/or supervised (pre-)training of CNNs,
GCNs,
GANs.
We developed two novel paradigms of self-supervised methods a)
Auto-Encoding Transformations (AET)
[pdf]
that learns Transformation-Equivariant Representations; b)
Adversarial Contrast (AdCo) that directly self-trains negative
pairs in contrastive learning approach.
- 1) Unsupervised
training of
CNNs: AETv1
[link][pdf][github]
and AETv2 [link],
- 2) Variational
AET and the connection to transformation-equivariant
representation learning [link][pdf][github],
- 3) (Semi-)Supervised
AET training with an ensemble of spatial and non-spatial
transformations [pdf][github],
- 4) GraphTER (Graph
Transformation Equivariant Representation): Unsupervised
training of Graph Convolutional Networks (GCNs) for 3D Scene
Understanding based on Point Cloud Analysis [pdf][github],
- 5) Transformation
GAN (TrGAN)
by using the AET loss to train the discriminator for better
generalization to create new images [pdf].
- 6) Adversarial
Contrast (AdCo)
[pdf][github]:
An adversarial contrastive learning method to directly train
negative samples end-to-end. It shows high performance to
pre-train ResNet-50
on ImageNet with
20% fewer epochs than the SOTA methods (e.g., MoCo v2, and BYOL)
while
achieving even better top-1 accuracy. The model is easy to implement
and can be used as a plug-in algorithm to combine with many
pre-training tasks.
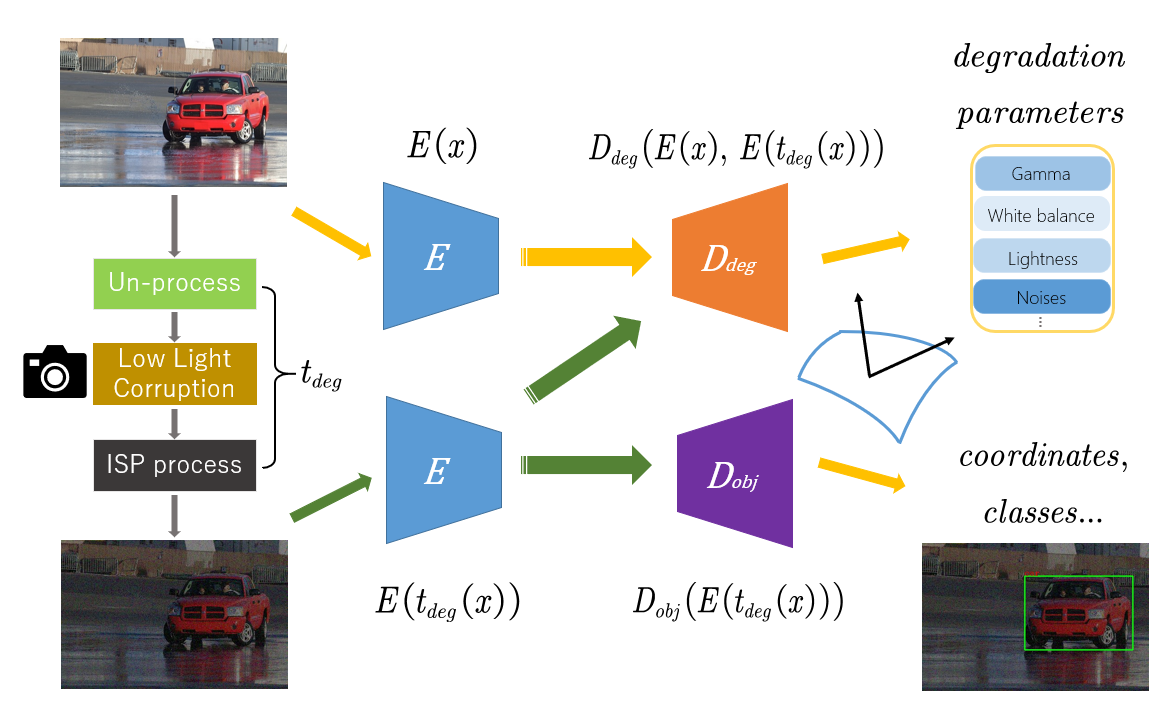
- 7) Multi-task AET
(MAET) for Dark Object Detection [pdf]:
We propose a multi-task AET for visual representation learning in
low-light environment for object detection. It applies an orthogonal
regularity among the tangents under both spatial and low-illumination
degrading transformations to minimize the cross-task
redundancy,
which delivers the SOTA performance on dark object detection.
(a) AutoEncoding Transformations (AET) [ pdf]
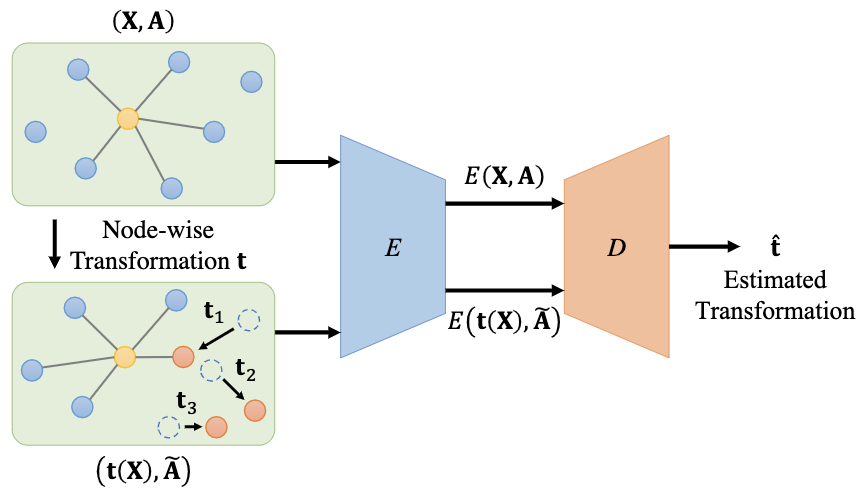 
(b)
Graph TER (GTER) [ pdf]
(c)
Multitask AET (MAET)
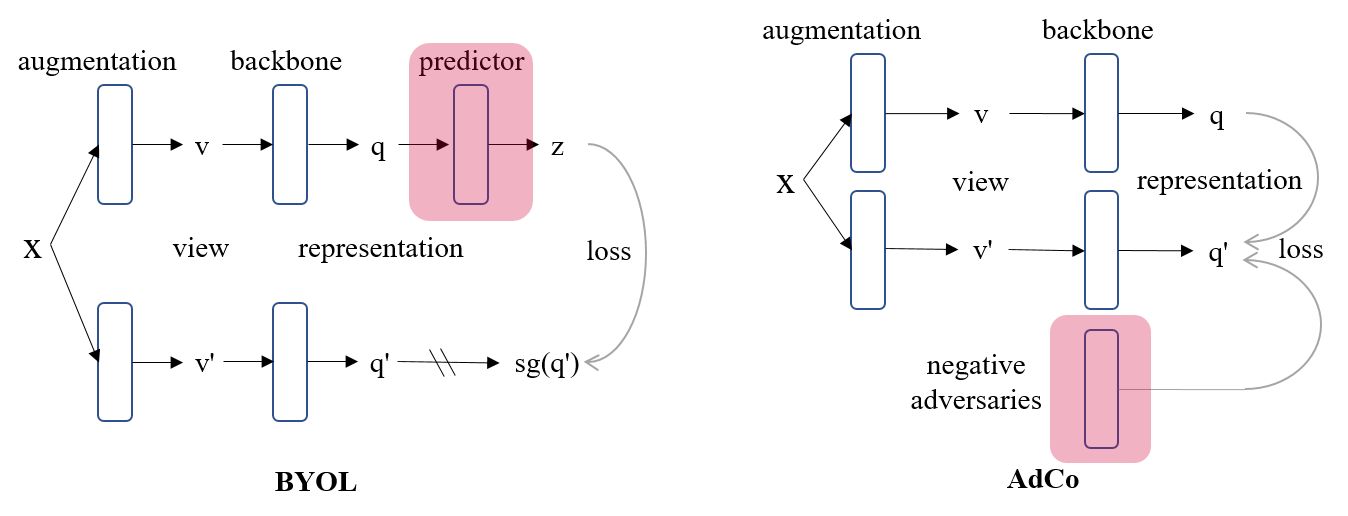
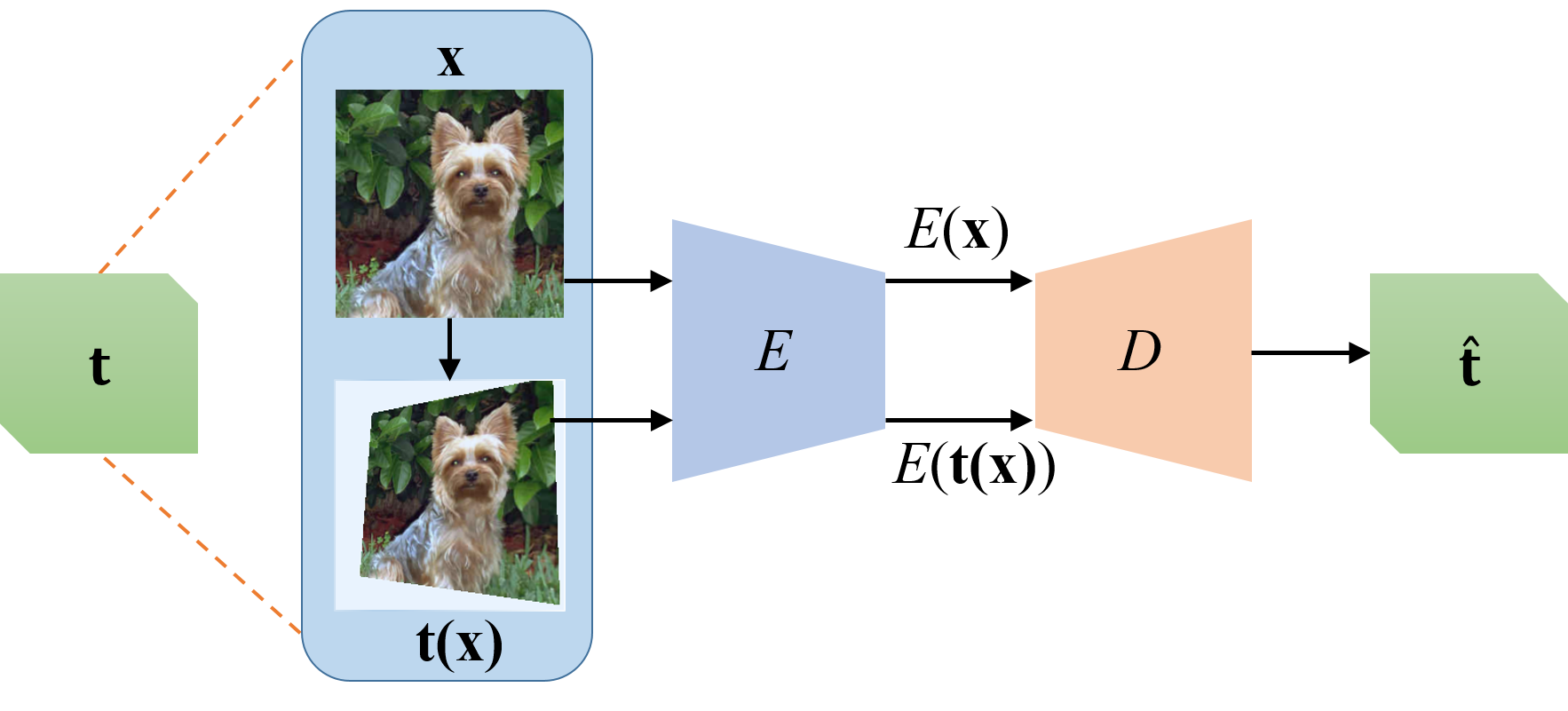
(d)
Comparison of BYOL vs. AdCo. While BYOL has to learn a multi-layer of
MLP predictor (highlighted in red) to estimate the represenation of the
other branch, AdCo [ pdf]
instead learns a single layer of negative adversaries. For the first
time, the AdCo shows the negative samples are learnable to track the
change of represenations over the pretraining course, with superior
performances on downstream tasks.
- [Regularized GANs and Applications
to Visual Content Synthesis and Manipulation] We
present a regularized Loss-Sensitive GAN (LS-GAN),
and extended it to a generalized version (GLS-GAN) with
many variants of regularized GANs as its special cases.
We proved both the distributional consistency and generalizability of
the LS-GAN with polynomial
sample complexity to generate new contents. See more
details about
- 1)
LS-GAN and GLS-GAN [pdf][github],
- 2) A landscape of
regularized GANs in a big picture [url],
- 3)
An
extension by obtaining an encoder of
input samples directly with
manifold
margins through the loss-sensitive GAN [github: torch,
blocks]
,
- 4)
The LS-GAN has been
adopted by Microsoft CNTK (Cognitive Toolkit) as a reference
regularized GAN model [link].
- 5)
Localized GAN was used to model the manifold of images along their
tangent vector spaces. It was used to capture and/or generate
the
local variants of input images so that their attributes can be edited
by manipulating the input noises. The local variants of
images
along the tangents can also be used to approximate
the Beltrami-Laplace operator for semi-supervised
representation
learning [pdf].
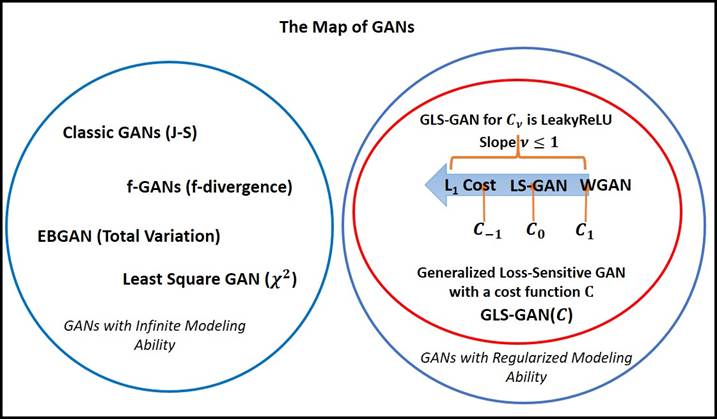
The map of conventional vs. regularized GANs, in which the GLS-GAN
contains all known regularized GANs as its special cases [ pdf]
[ url].
It provides a systematic plot of regularized GAN models found thus
far from both theoretic and practical perspectives. The proposed
metric,
Minimum Recontruction Error (MRE) [ pdf]
also gives a quantity measure of generalizability to generate and
synthesize new
contents out of existing examples. This demonstrates regularized GANs
such as LS-GAN and GLS-GAN are models not only merely memorizing
training examples, but also being able to create contents
never
seen before.
- Machine Learning for Internet-Of-Things (IOTs) and Multi-Source Analysis] We
developed 1) State-Frequency Memory RNNs [pdf]
for multiple-frequency analysis of signals, 2) Spatial-Temporal
Transfomers [pdf]
to integrate self-attentions over spatial topolgy and temporal
dynamics for traffic forecasting, and 3) First-Take-All
Hashing [pdf]
to efficiently index and retrieve multimodal sensor signals at
scale.
- 1) State-Frequency Memory (SFM)
RNNs for Multi-Source Signal/Financial Data Analysis. It
explores
multiple frequencies of
dynamic memory for time-series analysis through SFM RNNs.
The multi-frequency memory enables more accurate signal
predictions than
the LSTM in various ranges of dynamic contexts. For example, in
financial anlayis [pdf],
long-term investors use low-frequency information to
forecast asset prices, while
high-frequency traders rely more on high-frequency pricing signals to
make
investment decisions.
- 2) Spatial-Temporal Transformer and Applications to Traffic
Forecasting. The spatial-temporal transformer [pdf]
is among one of the first works to apply self-attention to
dynamic
graph neural networks by exploring both the network topology and
temporal
dynamics to forecast traffic flows from city-scale IOT data.
- 3) First-Take-All Hashing and
Deviced-Enabled Healthcare.
The First-Take-All (FTA) hashing was developed to
efficiently index dynamic activities captured by multimodal sensors
(cameras and depth sensors) [pdf]
fior eldercare, and image [pdf]
and cross-modal retrieval [pdf].
It is also applied to
classify singals of brain neural activities for early
diagnosis of
ADHD [pdf],
which is one order of magnitude faster than
the SOTA methods on the
multi-facility dataset in a Kaggle Challenge .
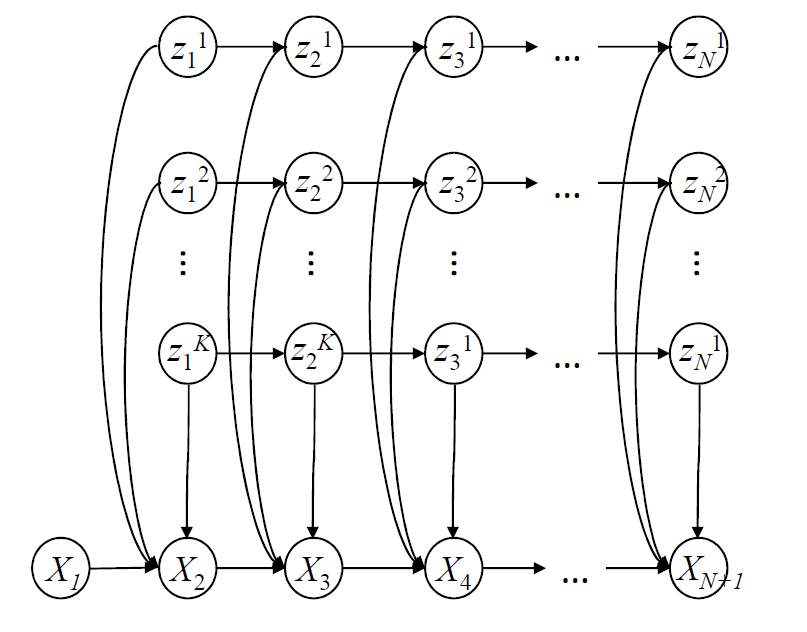
- 4) Temporal alignment between
Multi-Source
Signals.
We propose Dynamically Programmable Layers to
automatically align signals from multiple sources/devices. We
successfully demonstrate
its application to predict the brain connectivities between neurons [pdf].
- 5) Sensor Selection and Time-Series
Prediction. We propose State-Stacked
Sparseness [pdf]
for sensor selection and the Mixture
Factorized Ornstein-Uhlenbeck Process [pdf]
for time-series forecasting. The method considers the impact of both
faulty sensors (e.g., damaged and out-of-battery) and the change of
hidden states of the underlying mechanic/electric system for
time-series analysis and predictions.
- 6) E-Optimal Sensor Deployment and
Selection.
We develop an optimal online sensor selection approach with the
restricted isometry property based on e-optimality [link].
It was
successfully applied for collaborative spectrum sensing in cognitive
radio networks (CRNs), and selecting the most informative features from
a large amount of data/signals. The paper will be featured in
IEEE Computer's "Spotlight
on Transactions" Column.
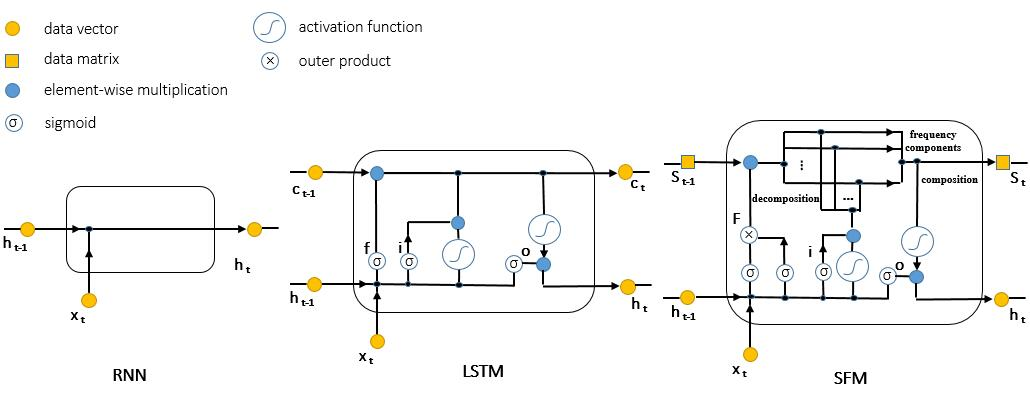
(a) Comparison of RNN, LSTM and SFM for finanical analysis [ pdf]
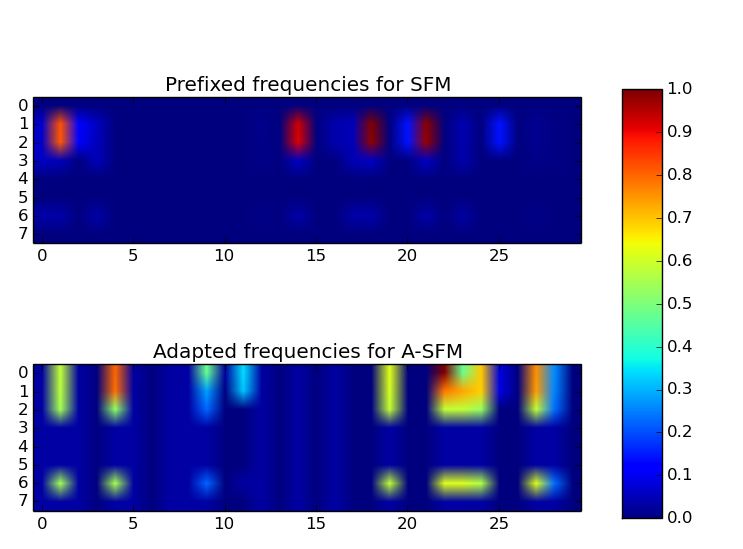
(b) Spectrum by SFM [ pdf]
(c)
MF Ornstein-Uhlenbeck Process [ pdf]
- [Small Data Challenges with
Limited Supervision]
Take a look at our survey of "Small
Data Challenges in Big Data Era: A
Survey of Recent Progress on Unsupervised and Semi-Supervised Methods"
[pdf],
and our tutorial presented at IJCAI 2019 [link]
with the presentation slides [pdf].
Also see our recent works on
- 1) Unsupervised Learning.
AutoEncoding Transformations (AET) [pdf],
Autoencoding Variational Transformations (AVT) [pdf],
GraphTER (Graph Transformation Equivariant Representations) [pdf], TrGANs
(Transformation GANs) [pdf],
- 2) Semi-Supervsied Learning.
Localized GANs (see how to compute Laplace-Beltrami operator directly
for semi-supervised learning) [pdf],
Ensemble AET [pdf],
- 3) Few-Shot Learning.
FLAT (Few-Short Learning via AET) [pdf],
knowledge Transfer for few-shot learning [pdf],
task-agnostic meta-learning [pdf]
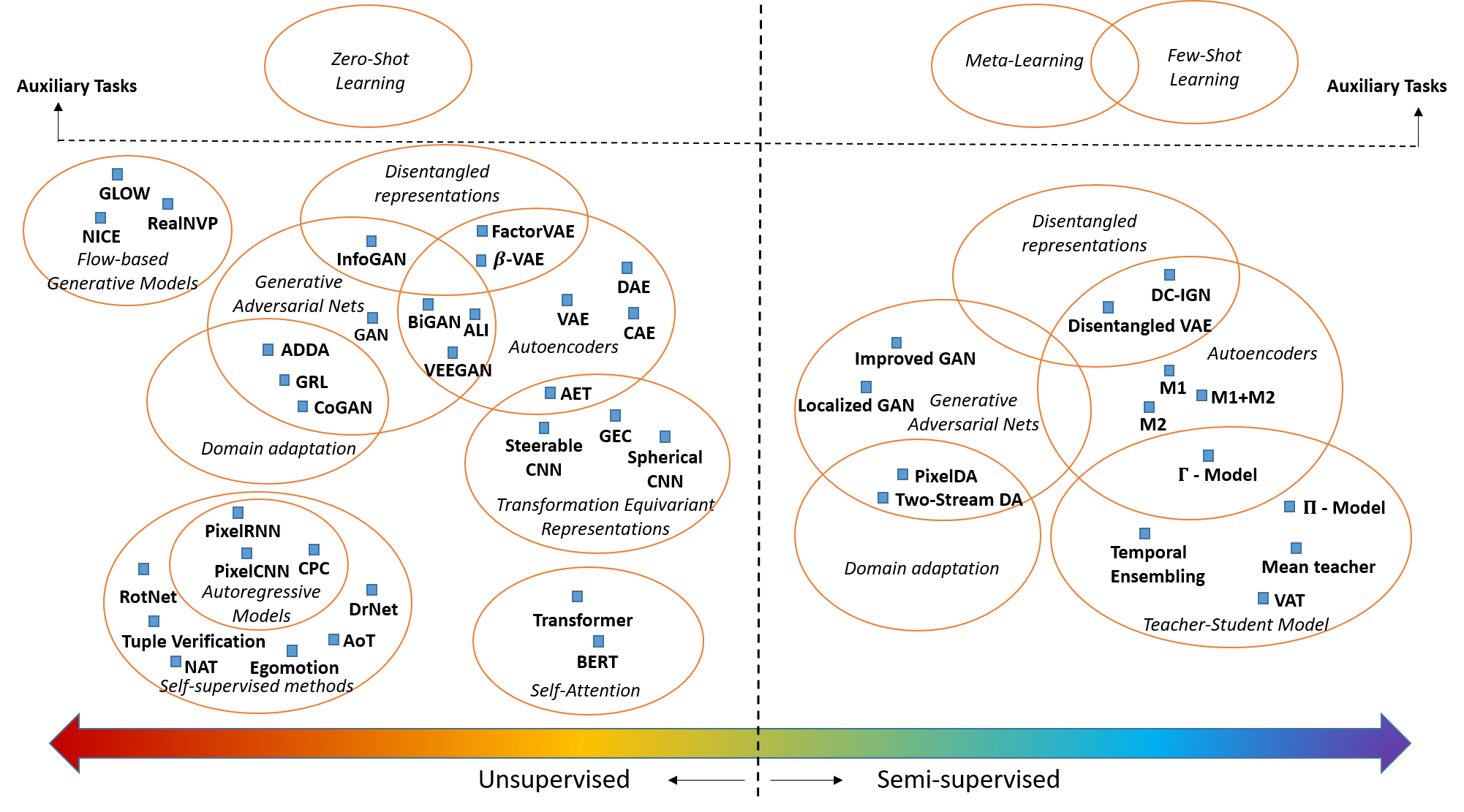
Overview of small data methods with limited or no supervision [ pdf]
- [MAPLE Github] We
are releasing the source code of our research projects
at our MAPLE github homepage [url].
We are inviting everyone interested in our works to
try them.
Feedbacks and pull requests are warmly welcome.
Back to top
|